[TLDR: Firefox caches intermediate CA certificates. A third-party website can infer which intermediates are cached by a user. To do this, it loads content from incorrectly configured hosts (missing intermediate in the provided certificate chain) and observes whether they load correctly (yes: corresponding intermediate was cached, no: it was not). Check out my proof of concept using more than 300 intermediate CAs. This technique can be used to gain a fingerprint for a user but also leaks semantic information (mainly geographical). Since Private Browsing mode does not isolate the cache, it can be used to link a Private Browsing user to her real profile. Furthermore, attackers could force users to visit correctly configured websites with unusal intermediates and thus set a kind of supercookie. This has been reported as #1334485 in the Mozilla bug tracker.]
The idea
A few months ago, I was sitting in Ivan Ristić’s course »The Best TLS Training in the World« (which I highly recommend, by the way). One thing Ivan was mentioning is the fact that probably the most common misconfiguration in setting up a TLS webserver is forgetting to deliver the complete certificate chain. Let me use some pictures to explain it. Here is the correct case:
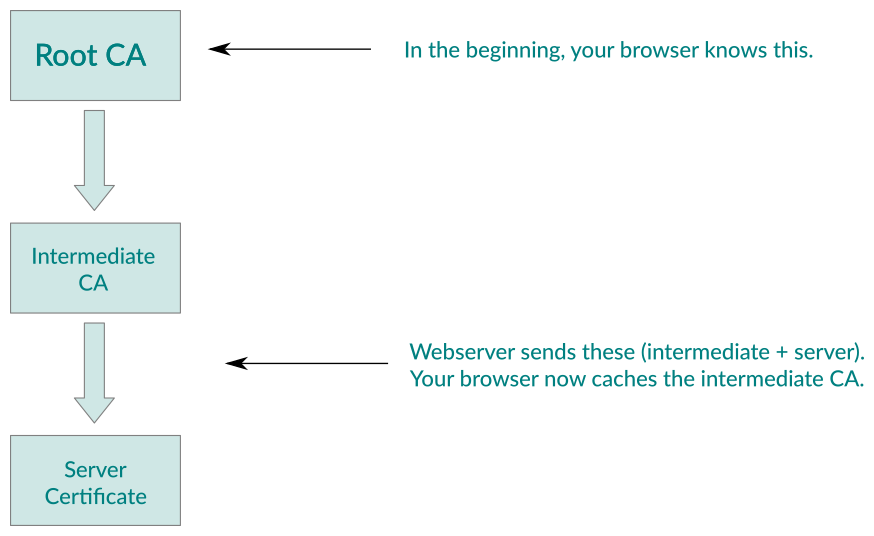
In case the server is misconfigured, the situation looks as follows:
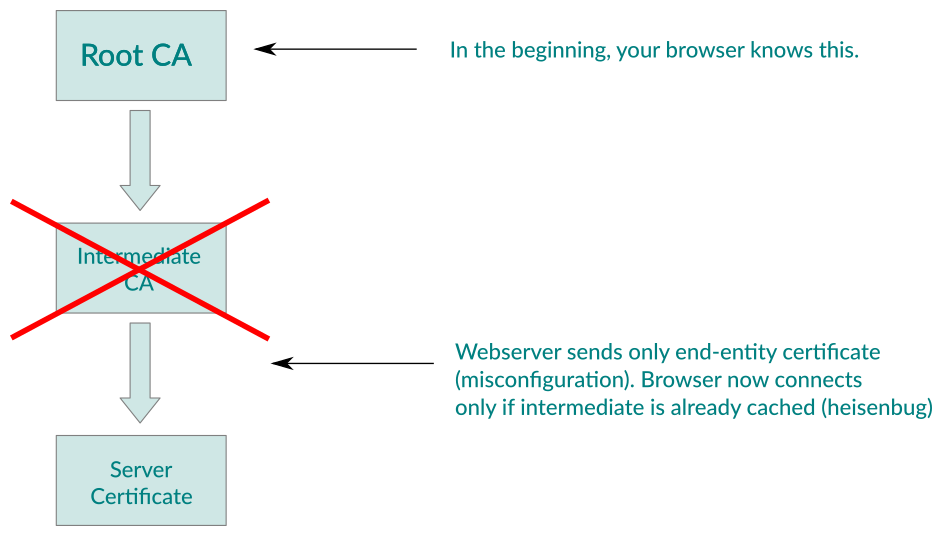
An idea came to my mind: if the behaviour is different depending on the cache, can I observe that from the outside? A quick look around on ssllabs.com for a site with incomplete chain and a <img src=https://brokensite/favicon.ico onload=alert(1) onerror=alert(2)> showed me that this was indeed feasible in Firefox (Chrome and Internet Explorer somehow both magically load the image/site even when the chain is not delivered − possibly using the caIssuer extension?). Interestingly enough, the cached CAs from the main profile were also used in Private Browsing mode.
Gathering data
Lurking around ssllabs.com to find new hosts with incomplete chains did not sound like a fun idea, and I guess Qualys would not have been too happy if I automated the process. So I had to come up with a better way to gather hosts for a proof of concept. Luckily, there are public datasets of the TLS server landscape available. The two that I ended up using were the Censys.io scan (free researcher account needed) and the Rapid7 Project Sonar (free to download) ones.
In the first step, I wanted to identify all possible intermediate CA certificates that chain up to a trusted root CA. For this, I downloaded the Root CA extract provided by the curl project. Then I looked at all CA certificates in the datasets and checked with openssl verify to see if they are a direct intermediate of one of the trusted roots. To further identify intermediate CAs that chain up to a trusted root in a longer path, I ran this process in an iterative fashion using the root CAs and already identified intermediates until no more new intermediates were found in the datasets. I ended up with 3366 individual CA certificates that chain up to a trusted root (1931 on the first level, 1286 on the second level, 92 on the third level and 57 on the fourth level).
The next step was identifying websites which were misconfigured. For this, the Project Sonar data came in handy as they scan the complete IPv4 internet and record the delivered certificate chain for each IP on port 443. Since they provide the certificates individually and the scan data only contains hashes of the chain elements, I first had to import all the certificates into a SQLite database in order to quickly look them up by hash. Despite ending up with a database file of roughly 100 GB, SQLite performed quite nicely. I then processed this data by looking at all certificates to see if they contained an issuer (by looking at the Authority Key Identifier extension) that was present in my set of CAs, but not delivered in the chain. If this was the case, I had identified the IP address of a misconfigured host. Now it was necessary to see if the certificate used a hostname which actually resolved to that IP address. If that was the case, I had a candidate for an incorrectly configured webserver.
The last step was to identify a working image on that webserver which can be loaded. I considered several options but settled on just loading the website in Firefox and observing using Burp which images were loaded. This left me with a Burp state file of several gigabytes and a list of plenty of URLs for more than 300 individual intermediate CAs.
The proof of concept
I used this list of URLs to build a proof of concept using elm, my favourite way to avoid writing JavaScript these days. Here is how a part of the output (and Firebug’s Net Panel to see which images are loaded) looks for me:
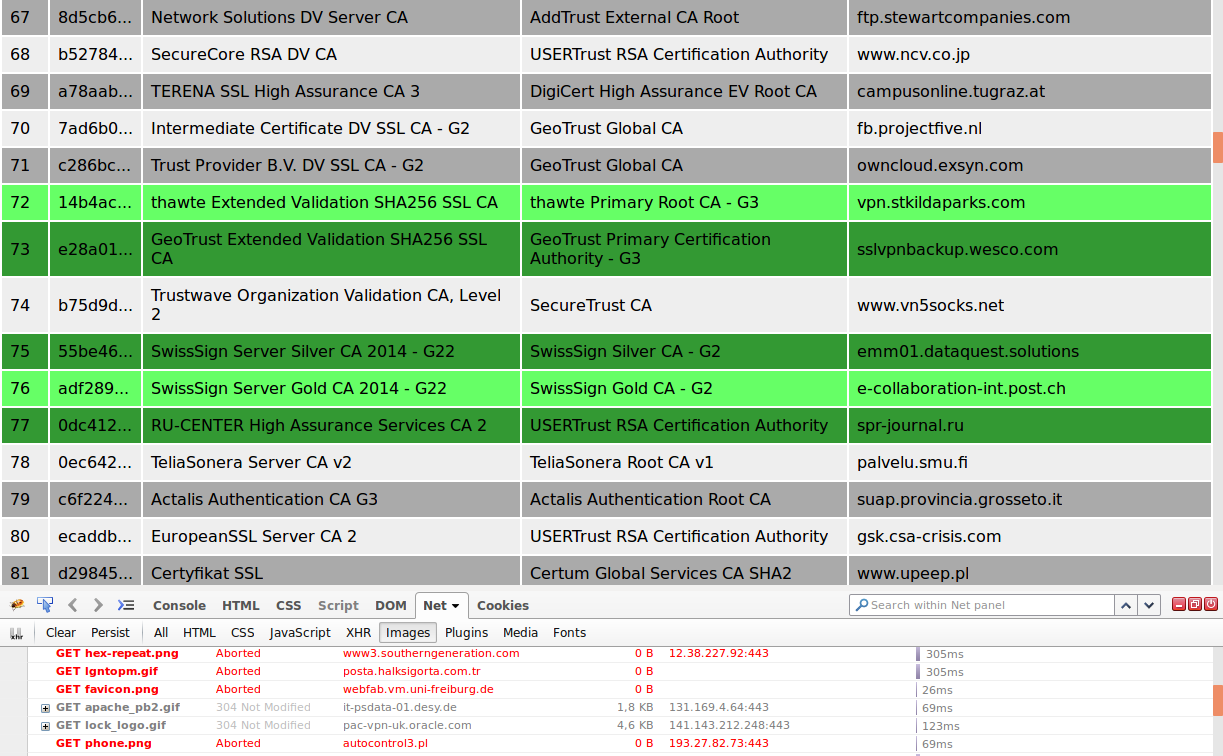
Note that it might occasionally contain false positives or false negatives, since the servers that are used for testing are not under my control and might change their TLS configuration and/or location of images.
If you run the proof of concept yourself, you will be presented with an option to share your result with me. Please do so − I am grateful for every data point obtained in this way to see what additional information can be extracted from it (geographical location? specific interests of the user? etc.).
Further ideas
One thing that is pretty easy to see is that this technique could also be used in a more active way by forcing users to visit correctly configured websites from unusual intermediates. Note that for example the PKI of the »Deutsches Forschungsnetzwerk« comes in handy here, as it provides literally hundreds of (managed) intermediates for their members, including lots of tiny universities or research institutes. One could force to user to cache a certain subset of unusal intermediates and then check later from a different domain which intermediates are set. This is of course not foolproof, since users might visit correctly configured websites from those intermediates and thus flip bits from 0 to 1. Error-correcting codes could be used here (with the tradeoff of having to use more intermediates) to deal with that problem.
In addition to the purely »statistical« view of having a fingerprint with a sequence of n bits representing the cache status for each tested CA, the fingerprint also contains additional semantic information. Certain CAs have customers mostly in one country or region, or might have even more specific use-cases which let’s you infer even more information − i.e. a user who has the »Deutsche Bundestag CA« cached is most probably located in Germany and probably at least somewhat interested in politics.
From an attacker’s perspective, this could also be used to check if the browser is running inside a malware analysis sandbox (which would probably have none or very few of the common intermediates cached) and delivering different content based on that information.
Solutions
I reported the problem on January 27th, 2017 to Mozilla in bug #1334485. The cleanest solution would obviously be to not connect to incorrectly configured servers, regardless of whether the intermediate is cached or not. Understandably, Mozilla is reluctant to implement that without knowing the impact. Thus bug #1336226 has been filed to implement some related telemetry − let’s see how that goes.
From a user’s perspective, at the moment I can only recommend to regularly clean up your profile (by creating a fresh one, cleaning it up from the Firefox UI or using the certutil command line tool). Alternatively, blocking third-party requests with an addon such as Request Policy might be useful since the attack obviously needs to make (a lot of) third-party requests.